Using Processors
Setup
A simple example how to set up a processor is given in Processing Data.
Fundamentals
A processor consumes messages from one or more input topics and produces messages to none or many output topics. It can (and will, in most cases) also have it’s own state.
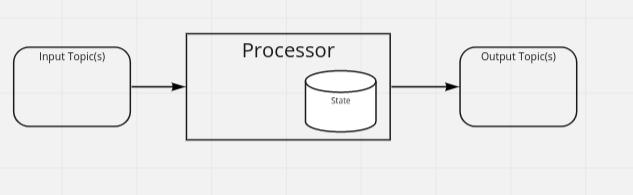
simplified processor
A processor state is called Table, since it follows key-value semantics stored in a key-value-store. The processor defining the table is the only instance allowed to write to that table.
Adding state introduces all kinds of race conditions, in particular in distributed and concurrent systems. So goka simplifies handling state by limiting any state changes to the currently processed key. That means, a value for a key can only be modified while processing a message with that key. Since messages of a single key are processed sequentially, there are no classic race conditions like lost update.
Suppose a processor is defined with the following group graph:
|
|
| Tables | Are | Cool |
|---|---|---|
| col 3 is | right-aligned | $1600 |
| col 2 is | centered | $12 |
| zebra stripes | are neat | $1 |
Under the hood, it’s not that simple though. In Kafka, topics are divided into partitions, each message belonging to a distinct partition. For each partition, a processor runs a PartitionProcessor of the input topic running in its own goroutine. That means, Goka processes messages in parallel across partitions, but sequentially within one partition.
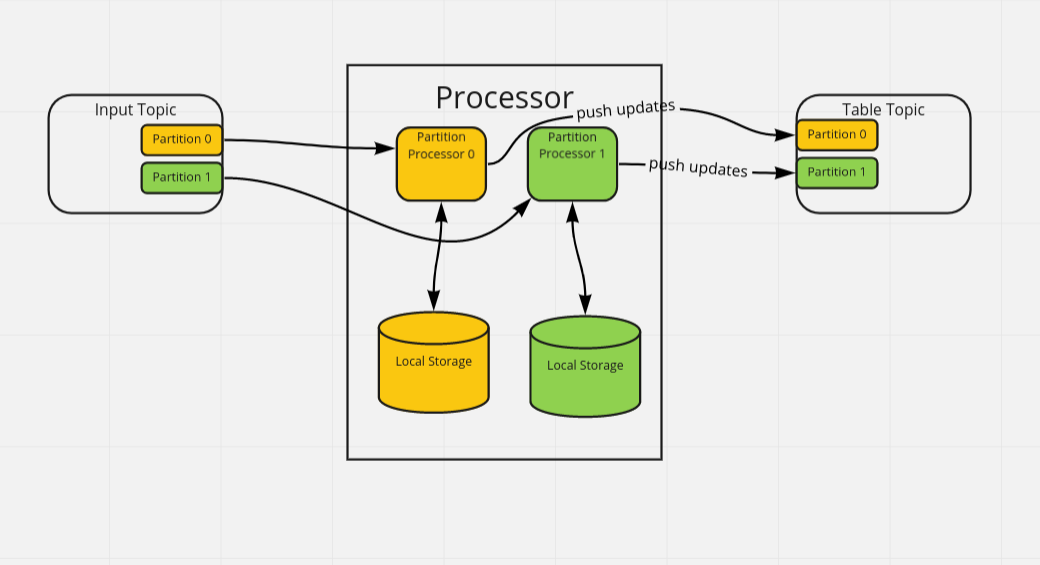
single processor
If multiple topics are consumed, they share the partition processors of the same topics. This is handled by Kafka via the Rebalance Protocol.
In a goka processor, the processor takes care of setting up a local storage syncing it with the current state in Kafka and consuming the messages from the assigned partitions.
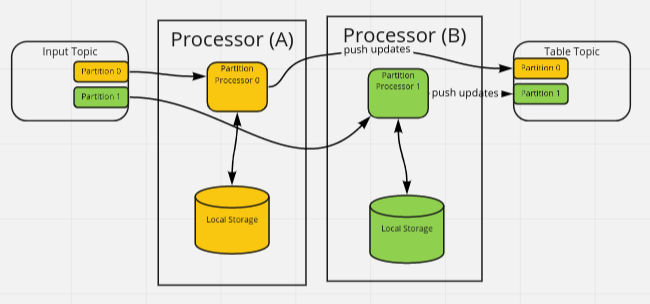
multiple instances by group
That implies some requirements:
- input topics need to have the same number of partitions
- the key needs to be used to assign a message to the partition deterministically (e.g. by hashing). This is called partitioning
- each key is only assigned to one partition
- partitioning needs to be the same across all input topics
Fulfilling those requirements, we can hide the notion of partitions from the goka user and create some guarantees based on the “key” of the message instead:
–> What’s state? how is it synced between kafka, who’s responsible?
- there are no race conditions for multiple messages of the same key. All messages will be processed sequentially
- writing the state
Lifecycle
- Load everything inside the table-topic –> it won’t get modified in the mean time as this instance will be the only one writing to it.
- start consuming which means -> read state from local disk, writechanges to local disk and the kafka topic